Przetestuj SWOJД„ FirmДҷ w Minuty
UtwГіrz konto i uruchom swojego chatbota AI w kilka minut. W peЕӮni konfigurowalny, bez koniecznoЕӣci kodowania - zacznij angaЕјowaДҮ swoich klientГіw natychmiast!
Gotowy w kilka minut
Nie wymaga programowania
100% bezpieczne
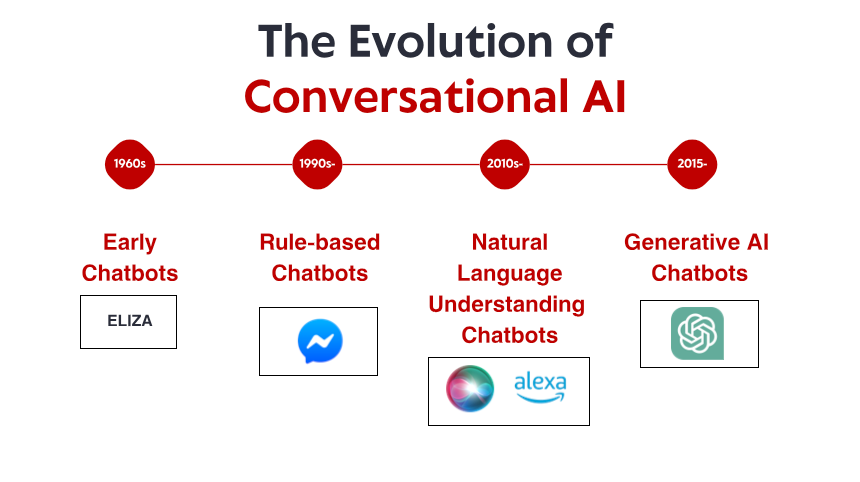
Skromne poczД…tki: wczesne systemy oparte na reguЕӮach
Historia konwersacyjnej sztucznej inteligencji zaczyna siДҷ w latach 60., na dЕӮugo zanim smartfony i asystenci gЕӮosowi stali siДҷ podstawowymi urzД…dzeniami gospodarstwa domowego. W maЕӮym laboratorium w MIT informatyk Joseph Weizenbaum stworzyЕӮ to, co wielu uwaЕјa za pierwszego chatbota: ELIZA. Zaprojektowana, aby symulowaДҮ psychoterapeutДҷ Rogersa, ELIZA dziaЕӮaЕӮa poprzez proste reguЕӮy dopasowywania wzorcГіw i podstawiania. Gdy uЕјytkownik wpisywaЕӮ вҖһJestem smutnyвҖқ, ELIZA mogЕӮa odpowiedzieДҮ вҖһDlaczego jesteЕӣ smutny?вҖқ вҖ“ tworzД…c iluzjДҷ zrozumienia poprzez przeformuЕӮowanie stwierdzeЕ„ w pytania.
To, co czyniЕӮo ELIZДҳ niezwykЕӮД…, to nie jej wyrafinowanie techniczne вҖ“ wedЕӮug dzisiejszych standardГіw program byЕӮ niesamowicie prosty. Raczej gЕӮДҷboki wpЕӮyw, jaki wywarЕӮ na uЕјytkownikГіw. Pomimo ЕӣwiadomoЕӣci, Ејe rozmawiajД… z programem komputerowym bez rzeczywistego zrozumienia, wiele osГіb nawiД…zaЕӮo emocjonalne wiДҷzi z ELIZД„, dzielД…c siДҷ gЕӮДҷboko osobistymi myЕӣlami i uczuciami. To zjawisko, ktГіre sam Weizenbaum uwaЕјaЕӮ za niepokojД…ce, ujawniЕӮo coЕӣ fundamentalnego na temat psychologii czЕӮowieka i naszej gotowoЕӣci do antropomorfizacji nawet najprostszych interfejsГіw konwersacyjnych.
Przez lata 70. i 80. oparte na reguЕӮach chatboty podД…ЕјaЕӮy za szablonem ELIZY, wprowadzajД…c stopniowe ulepszenia. Programy takie jak PARRY (symulujД…cy schizofrenika paranoidalnego) i RACTER (ktГіry вҖһbyЕӮ autoremвҖқ ksiД…Ејki zatytuЕӮowanej вҖһThe Policeman's Beard is Half ConstructedвҖқ) pozostaЕӮy mocno w paradygmacie opartym na reguЕӮach вҖ“ wykorzystujД…c wstДҷpnie zdefiniowane wzorce, dopasowywanie sЕӮГіw kluczowych i szablonowe odpowiedzi.
Te wczesne systemy miaЕӮy powaЕјne ograniczenia. Nie mogЕӮy w rzeczywistoЕӣci rozumieДҮ jДҷzyka, uczyДҮ siДҷ z interakcji ani dostosowywaДҮ siДҷ do nieoczekiwanych danych wejЕӣciowych. Ich wiedza ograniczaЕӮa siДҷ do reguЕӮ wyraЕәnie zdefiniowanych przez ich programistГіw. Kiedy uЕјytkownicy nieuchronnie wykraczali poza te granice, iluzja inteligencji szybko siДҷ rozpadaЕӮa, ujawniajД…c mechanicznД… naturДҷ pod spodem. Pomimo tych ograniczeЕ„ te pionierskie systemy ustanowiЕӮy fundament, na ktГіrym zbuduje siДҷ caЕӮa przyszЕӮa konwersacyjna sztuczna inteligencja.
To, co czyniЕӮo ELIZДҳ niezwykЕӮД…, to nie jej wyrafinowanie techniczne вҖ“ wedЕӮug dzisiejszych standardГіw program byЕӮ niesamowicie prosty. Raczej gЕӮДҷboki wpЕӮyw, jaki wywarЕӮ na uЕјytkownikГіw. Pomimo ЕӣwiadomoЕӣci, Ејe rozmawiajД… z programem komputerowym bez rzeczywistego zrozumienia, wiele osГіb nawiД…zaЕӮo emocjonalne wiДҷzi z ELIZД„, dzielД…c siДҷ gЕӮДҷboko osobistymi myЕӣlami i uczuciami. To zjawisko, ktГіre sam Weizenbaum uwaЕјaЕӮ za niepokojД…ce, ujawniЕӮo coЕӣ fundamentalnego na temat psychologii czЕӮowieka i naszej gotowoЕӣci do antropomorfizacji nawet najprostszych interfejsГіw konwersacyjnych.
Przez lata 70. i 80. oparte na reguЕӮach chatboty podД…ЕјaЕӮy za szablonem ELIZY, wprowadzajД…c stopniowe ulepszenia. Programy takie jak PARRY (symulujД…cy schizofrenika paranoidalnego) i RACTER (ktГіry вҖһbyЕӮ autoremвҖқ ksiД…Ејki zatytuЕӮowanej вҖһThe Policeman's Beard is Half ConstructedвҖқ) pozostaЕӮy mocno w paradygmacie opartym na reguЕӮach вҖ“ wykorzystujД…c wstДҷpnie zdefiniowane wzorce, dopasowywanie sЕӮГіw kluczowych i szablonowe odpowiedzi.
Te wczesne systemy miaЕӮy powaЕјne ograniczenia. Nie mogЕӮy w rzeczywistoЕӣci rozumieДҮ jДҷzyka, uczyДҮ siДҷ z interakcji ani dostosowywaДҮ siДҷ do nieoczekiwanych danych wejЕӣciowych. Ich wiedza ograniczaЕӮa siДҷ do reguЕӮ wyraЕәnie zdefiniowanych przez ich programistГіw. Kiedy uЕјytkownicy nieuchronnie wykraczali poza te granice, iluzja inteligencji szybko siДҷ rozpadaЕӮa, ujawniajД…c mechanicznД… naturДҷ pod spodem. Pomimo tych ograniczeЕ„ te pionierskie systemy ustanowiЕӮy fundament, na ktГіrym zbuduje siДҷ caЕӮa przyszЕӮa konwersacyjna sztuczna inteligencja.
Rewolucja wiedzy: systemy eksperckie i ustrukturyzowane informacje
Lata 80. i poczД…tek lat 90. to czas rozwoju systemГіw eksperckich вҖ“ programГіw AI zaprojektowanych do rozwiД…zywania zЕӮoЕјonych problemГіw poprzez naЕӣladowanie zdolnoЕӣci podejmowania decyzji przez ekspertГіw w okreЕӣlonych dziedzinach. ChoДҮ nie zostaЕӮy zaprojektowane przede wszystkim do konwersacji, systemy te stanowiЕӮy waЕјny krok ewolucyjny dla konwersacyjnej AI, wprowadzajД…c bardziej wyrafinowanД… reprezentacjДҷ wiedzy.
Systemy eksperckie, takie jak MYCIN (ktГіry diagnozowaЕӮ infekcje bakteryjne) i DENDRAL (ktГіry identyfikowaЕӮ zwiД…zki chemiczne), organizowaЕӮy informacje w ustrukturyzowanych bazach wiedzy i wykorzystywaЕӮy silniki wnioskowania do wyciД…gania wnioskГіw. W przypadku zastosowania w interfejsach konwersacyjnych podejЕӣcie to pozwoliЕӮo chatbotom wyjЕӣДҮ poza proste dopasowywanie wzorcГіw w kierunku czegoЕӣ przypominajД…cego rozumowanie вҖ“ przynajmniej w wД…skich dziedzinach.
Firmy zaczДҷЕӮy wdraЕјaДҮ praktyczne aplikacje, takie jak zautomatyzowane systemy obsЕӮugi klienta, wykorzystujД…c tДҷ technologiДҷ. Systemy te zazwyczaj wykorzystywaЕӮy drzewa decyzyjne i interakcje oparte na menu, a nie konwersacje swobodne, ale stanowiЕӮy wczesne prГіby automatyzacji interakcji, ktГіre wczeЕӣniej wymagaЕӮy interwencji czЕӮowieka.
Ograniczenia pozostaЕӮy znaczД…ce. Systemy te byЕӮy kruche i nie byЕӮy w stanie sprawnie obsЕӮugiwaДҮ nieoczekiwanych danych wejЕӣciowych. WymagaЕӮy ogromnego wysiЕӮku ze strony inЕјynierГіw wiedzy, aby rДҷcznie kodowaДҮ informacje i reguЕӮy. I co moЕјe najwaЕјniejsze, nadal nie potrafili w peЕӮni zrozumieДҮ jДҷzyka naturalnego w jego peЕӮnej zЕӮoЕјonoЕӣci i niejednoznacznoЕӣci.
Niemniej jednak ta epoka ustanowiЕӮa waЕјne koncepcje, ktГіre pГіЕәniej miaЕӮy staДҮ siДҷ kluczowe dla wspГіЕӮczesnej konwersacyjnej sztucznej inteligencji: ustrukturyzowanД… reprezentacjДҷ wiedzy, logiczne wnioskowanie i specjalizacjДҷ domenowД…. Scena byЕӮa przygotowywana do zmiany paradygmatu, chociaЕј technologia jeszcze nie byЕӮa gotowa.
Systemy eksperckie, takie jak MYCIN (ktГіry diagnozowaЕӮ infekcje bakteryjne) i DENDRAL (ktГіry identyfikowaЕӮ zwiД…zki chemiczne), organizowaЕӮy informacje w ustrukturyzowanych bazach wiedzy i wykorzystywaЕӮy silniki wnioskowania do wyciД…gania wnioskГіw. W przypadku zastosowania w interfejsach konwersacyjnych podejЕӣcie to pozwoliЕӮo chatbotom wyjЕӣДҮ poza proste dopasowywanie wzorcГіw w kierunku czegoЕӣ przypominajД…cego rozumowanie вҖ“ przynajmniej w wД…skich dziedzinach.
Firmy zaczДҷЕӮy wdraЕјaДҮ praktyczne aplikacje, takie jak zautomatyzowane systemy obsЕӮugi klienta, wykorzystujД…c tДҷ technologiДҷ. Systemy te zazwyczaj wykorzystywaЕӮy drzewa decyzyjne i interakcje oparte na menu, a nie konwersacje swobodne, ale stanowiЕӮy wczesne prГіby automatyzacji interakcji, ktГіre wczeЕӣniej wymagaЕӮy interwencji czЕӮowieka.
Ograniczenia pozostaЕӮy znaczД…ce. Systemy te byЕӮy kruche i nie byЕӮy w stanie sprawnie obsЕӮugiwaДҮ nieoczekiwanych danych wejЕӣciowych. WymagaЕӮy ogromnego wysiЕӮku ze strony inЕјynierГіw wiedzy, aby rДҷcznie kodowaДҮ informacje i reguЕӮy. I co moЕјe najwaЕјniejsze, nadal nie potrafili w peЕӮni zrozumieДҮ jДҷzyka naturalnego w jego peЕӮnej zЕӮoЕјonoЕӣci i niejednoznacznoЕӣci.
Niemniej jednak ta epoka ustanowiЕӮa waЕјne koncepcje, ktГіre pГіЕәniej miaЕӮy staДҮ siДҷ kluczowe dla wspГіЕӮczesnej konwersacyjnej sztucznej inteligencji: ustrukturyzowanД… reprezentacjДҷ wiedzy, logiczne wnioskowanie i specjalizacjДҷ domenowД…. Scena byЕӮa przygotowywana do zmiany paradygmatu, chociaЕј technologia jeszcze nie byЕӮa gotowa.
Rozumienie jДҷzyka naturalnego: przeЕӮom w lingwistyce obliczeniowej
Pod koniec lat 90. i na poczД…tku XXI wieku zaczДҷto zwracaДҮ coraz wiДҷkszД… uwagДҷ na przetwarzanie jДҷzyka naturalnego (NLP) i lingwistykДҷ obliczeniowД…. Zamiast prГіbowaДҮ rДҷcznie kodowaДҮ reguЕӮy dla kaЕјdej moЕјliwej interakcji, naukowcy zaczДҷli opracowywaДҮ metody statystyczne, aby pomГіc komputerom zrozumieДҮ inherentne wzorce jДҷzyka ludzkiego.
Ta zmiana byЕӮa moЕјliwa dziДҷki kilku czynnikom: rosnД…cej mocy obliczeniowej, lepszym algorytmom i, co najwaЕјniejsze, dostДҷpnoЕӣci duЕјych korpusГіw tekstowych, ktГіre moЕјna byЕӮo analizowaДҮ w celu identyfikacji wzorcГіw jДҷzykowych. Systemy zaczДҷЕӮy wЕӮД…czaДҮ techniki takie jak:
Tagging czДҷЕӣci mowy: Identyfikowanie, czy sЕӮowa funkcjonujД… jako rzeczowniki, czasowniki, przymiotniki itp.
Rozpoznawanie nazwanych bytГіw: Wykrywanie i klasyfikowanie nazw wЕӮasnych (ludzie, organizacje, lokalizacje).
Analiza sentymentГіw: OkreЕӣlanie emocjonalnego tonu tekstu.
Analiza skЕӮadniowa: Analiza struktury zdania w celu identyfikacji relacji gramatycznych miДҷdzy sЕӮowami.
Jednym z przeЕӮomowych rozwiД…zaЕ„ byЕӮ Watson firmy IBM, ktГіry w 2011 roku pokonaЕӮ ludzkich mistrzГіw w teleturnieju Jeopardy! ChociaЕј nie byЕӮ to ЕӣciЕӣle system konwersacyjny, Watson wykazaЕӮ siДҷ bezprecedensowymi umiejДҷtnoЕӣciami rozumienia pytaЕ„ w jДҷzyku naturalnym, przeszukiwania ogromnych repozytoriГіw wiedzy i formuЕӮowania odpowiedzi вҖ” umiejДҷtnoЕӣciami, ktГіre miaЕӮy okazaДҮ siДҷ niezbДҷdne dla nastДҷpnej generacji chatbotГіw.
WkrГіtce pojawiЕӮy siДҷ aplikacje komercyjne. W 2011 roku uruchomiono Siri firmy Apple, udostДҷpniajД…c interfejsy konwersacyjne przeciДҷtnym konsumentom. ChoДҮ Siri jest ograniczona przez dzisiejsze standardy, stanowiЕӮa znaczД…cy postДҷp w udostДҷpnianiu asystentГіw AI zwykЕӮym uЕјytkownikom. PГіЕәniej pojawiЕӮy siДҷ Cortana firmy Microsoft, Asystent Google i Alexa firmy Amazon, z ktГіrych kaЕјdy wprowadzaЕӮ najnowoczeЕӣniejsze rozwiД…zania w zakresie konwersacyjnej sztucznej inteligencji skierowanej do konsumentГіw.
Pomimo tych postДҷpГіw systemy z tej ery nadal miaЕӮy problemy z kontekstem, rozumowaniem opartym na zdrowym rozsД…dku i generowaniem prawdziwie naturalnie brzmiД…cych odpowiedzi. ByЕӮy bardziej wyrafinowane niЕј ich przodkowie bazujД…cy na reguЕӮach, ale pozostaЕӮy zasadniczo ograniczone w rozumieniu jДҷzyka i Еӣwiata.
Ta zmiana byЕӮa moЕјliwa dziДҷki kilku czynnikom: rosnД…cej mocy obliczeniowej, lepszym algorytmom i, co najwaЕјniejsze, dostДҷpnoЕӣci duЕјych korpusГіw tekstowych, ktГіre moЕјna byЕӮo analizowaДҮ w celu identyfikacji wzorcГіw jДҷzykowych. Systemy zaczДҷЕӮy wЕӮД…czaДҮ techniki takie jak:
Tagging czДҷЕӣci mowy: Identyfikowanie, czy sЕӮowa funkcjonujД… jako rzeczowniki, czasowniki, przymiotniki itp.
Rozpoznawanie nazwanych bytГіw: Wykrywanie i klasyfikowanie nazw wЕӮasnych (ludzie, organizacje, lokalizacje).
Analiza sentymentГіw: OkreЕӣlanie emocjonalnego tonu tekstu.
Analiza skЕӮadniowa: Analiza struktury zdania w celu identyfikacji relacji gramatycznych miДҷdzy sЕӮowami.
Jednym z przeЕӮomowych rozwiД…zaЕ„ byЕӮ Watson firmy IBM, ktГіry w 2011 roku pokonaЕӮ ludzkich mistrzГіw w teleturnieju Jeopardy! ChociaЕј nie byЕӮ to ЕӣciЕӣle system konwersacyjny, Watson wykazaЕӮ siДҷ bezprecedensowymi umiejДҷtnoЕӣciami rozumienia pytaЕ„ w jДҷzyku naturalnym, przeszukiwania ogromnych repozytoriГіw wiedzy i formuЕӮowania odpowiedzi вҖ” umiejДҷtnoЕӣciami, ktГіre miaЕӮy okazaДҮ siДҷ niezbДҷdne dla nastДҷpnej generacji chatbotГіw.
WkrГіtce pojawiЕӮy siДҷ aplikacje komercyjne. W 2011 roku uruchomiono Siri firmy Apple, udostДҷpniajД…c interfejsy konwersacyjne przeciДҷtnym konsumentom. ChoДҮ Siri jest ograniczona przez dzisiejsze standardy, stanowiЕӮa znaczД…cy postДҷp w udostДҷpnianiu asystentГіw AI zwykЕӮym uЕјytkownikom. PГіЕәniej pojawiЕӮy siДҷ Cortana firmy Microsoft, Asystent Google i Alexa firmy Amazon, z ktГіrych kaЕјdy wprowadzaЕӮ najnowoczeЕӣniejsze rozwiД…zania w zakresie konwersacyjnej sztucznej inteligencji skierowanej do konsumentГіw.
Pomimo tych postДҷpГіw systemy z tej ery nadal miaЕӮy problemy z kontekstem, rozumowaniem opartym na zdrowym rozsД…dku i generowaniem prawdziwie naturalnie brzmiД…cych odpowiedzi. ByЕӮy bardziej wyrafinowane niЕј ich przodkowie bazujД…cy na reguЕӮach, ale pozostaЕӮy zasadniczo ograniczone w rozumieniu jДҷzyka i Еӣwiata.
Uczenie maszynowe i podejЕӣcie oparte na danych
PoЕӮowa lat 2010. oznaczaЕӮa kolejnД… zmianДҷ paradygmatu w konwersacyjnej sztucznej inteligencji wraz z powszechnym przyjДҷciem technik uczenia maszynowego. Zamiast polegaДҮ na rДҷcznie tworzonych reguЕӮach lub ograniczonych modelach statystycznych, inЕјynierowie zaczДҷli budowaДҮ systemy, ktГіre mogЕӮy uczyДҮ siДҷ wzorcГіw bezpoЕӣrednio z danych вҖ” i to mnГіstwa danych.
W tej epoce nastД…piЕӮ wzrost klasyfikacji intencji i ekstrakcji encji jako podstawowych komponentГіw architektury konwersacyjnej. Gdy uЕјytkownik skЕӮadaЕӮ ЕјД…danie, system:
KlasyfikowaЕӮ ogГіlnД… intencjДҷ (np. rezerwacjДҷ lotu, sprawdzenie pogody, odtwarzanie muzyki)
EkstrahowaЕӮ odpowiednie encje (np. lokalizacje, daty, tytuЕӮy piosenek)
MapowaЕӮ je na okreЕӣlone dziaЕӮania lub odpowiedzi
Uruchomienie przez Facebooka (obecnie Meta) platformy Messenger w 2016 r. umoЕјliwiЕӮo programistom tworzenie chatbotГіw, ktГіre mogЕӮy dotrzeДҮ do milionГіw uЕјytkownikГіw, wywoЕӮujД…c falДҷ zainteresowania komercyjnego. Wiele firm spieszyЕӮo siДҷ z wdraЕјaniem chatbotГіw, chociaЕј wyniki byЕӮy rГіЕјne. Wczesne komercyjne wdroЕјenia czДҷsto frustrowaЕӮy uЕјytkownikГіw ograniczonym zrozumieniem i sztywnymi przepЕӮywami konwersacji.
W tym okresie ewoluowaЕӮa rГіwnieЕј architektura techniczna systemГіw konwersacyjnych. Typowe podejЕӣcie obejmowaЕӮo potok wyspecjalizowanych komponentГіw:
Automatyczne rozpoznawanie mowy (dla interfejsГіw gЕӮosowych)
Rozumienie jДҷzyka naturalnego
ZarzД…dzanie dialogiem
Generowanie jДҷzyka naturalnego
Tekst na mowДҷ (dla interfejsГіw gЕӮosowych)
KaЕјdy komponent moЕјna byЕӮo zoptymalizowaДҮ osobno, co pozwalaЕӮo na stopniowe ulepszenia. Jednak te architektury potokowe czasami cierpiaЕӮy na propagacjДҷ bЕӮДҷdГіw вҖ“ bЕӮДҷdy na wczesnych etapach kaskadowo przechodziЕӮy przez system.
ChociaЕј uczenie maszynowe znacznie poprawiЕӮo moЕјliwoЕӣci, systemy nadal miaЕӮy problemy z utrzymaniem kontekstu podczas dЕӮugich konwersacji, zrozumieniem ukrytych informacji i generowaniem naprawdДҷ zrГіЕјnicowanych i naturalnych odpowiedzi. Kolejny przeЕӮom wymagaЕӮ bardziej radykalnego podejЕӣcia.
W tej epoce nastД…piЕӮ wzrost klasyfikacji intencji i ekstrakcji encji jako podstawowych komponentГіw architektury konwersacyjnej. Gdy uЕјytkownik skЕӮadaЕӮ ЕјД…danie, system:
KlasyfikowaЕӮ ogГіlnД… intencjДҷ (np. rezerwacjДҷ lotu, sprawdzenie pogody, odtwarzanie muzyki)
EkstrahowaЕӮ odpowiednie encje (np. lokalizacje, daty, tytuЕӮy piosenek)
MapowaЕӮ je na okreЕӣlone dziaЕӮania lub odpowiedzi
Uruchomienie przez Facebooka (obecnie Meta) platformy Messenger w 2016 r. umoЕјliwiЕӮo programistom tworzenie chatbotГіw, ktГіre mogЕӮy dotrzeДҮ do milionГіw uЕјytkownikГіw, wywoЕӮujД…c falДҷ zainteresowania komercyjnego. Wiele firm spieszyЕӮo siДҷ z wdraЕјaniem chatbotГіw, chociaЕј wyniki byЕӮy rГіЕјne. Wczesne komercyjne wdroЕјenia czДҷsto frustrowaЕӮy uЕјytkownikГіw ograniczonym zrozumieniem i sztywnymi przepЕӮywami konwersacji.
W tym okresie ewoluowaЕӮa rГіwnieЕј architektura techniczna systemГіw konwersacyjnych. Typowe podejЕӣcie obejmowaЕӮo potok wyspecjalizowanych komponentГіw:
Automatyczne rozpoznawanie mowy (dla interfejsГіw gЕӮosowych)
Rozumienie jДҷzyka naturalnego
ZarzД…dzanie dialogiem
Generowanie jДҷzyka naturalnego
Tekst na mowДҷ (dla interfejsГіw gЕӮosowych)
KaЕјdy komponent moЕјna byЕӮo zoptymalizowaДҮ osobno, co pozwalaЕӮo na stopniowe ulepszenia. Jednak te architektury potokowe czasami cierpiaЕӮy na propagacjДҷ bЕӮДҷdГіw вҖ“ bЕӮДҷdy na wczesnych etapach kaskadowo przechodziЕӮy przez system.
ChociaЕј uczenie maszynowe znacznie poprawiЕӮo moЕјliwoЕӣci, systemy nadal miaЕӮy problemy z utrzymaniem kontekstu podczas dЕӮugich konwersacji, zrozumieniem ukrytych informacji i generowaniem naprawdДҷ zrГіЕјnicowanych i naturalnych odpowiedzi. Kolejny przeЕӮom wymagaЕӮ bardziej radykalnego podejЕӣcia.
Rewolucja TransformerГіw: Modele JДҷzyka Neuronalnego
Rok 2017 byЕӮ przeЕӮomowym momentem w historii sztucznej inteligencji wraz z publikacjД… вҖһAttention Is All You NeedвҖқ, wprowadzajД…c architekturДҷ Transformer, ktГіra zrewolucjonizowaЕӮa przetwarzanie jДҷzyka naturalnego. W przeciwieЕ„stwie do poprzednich podejЕӣДҮ, ktГіre przetwarzaЕӮy tekst sekwencyjnie, Transformers mogЕӮy jednoczeЕӣnie rozwaЕјaДҮ caЕӮy fragment, co pozwalaЕӮo im lepiej uchwyciДҮ relacje miДҷdzy sЕӮowami niezaleЕјnie od ich odlegЕӮoЕӣci od siebie.
Ta innowacja umoЕјliwiЕӮa rozwГіj coraz potДҷЕјniejszych modeli jДҷzykowych. W 2018 roku Google wprowadziЕӮo BERT (Bidirectional Encoder Representations from Transformers), co radykalnie poprawiЕӮo wydajnoЕӣДҮ w rГіЕјnych zadaniach zwiД…zanych ze zrozumieniem jДҷzyka. W 2019 roku OpenAI wydaЕӮo GPT-2, demonstrujД…c bezprecedensowe moЕјliwoЕӣci generowania spГіjnego, kontekstowo istotnego tekstu.
Najbardziej spektakularny skok nastД…piЕӮ w 2020 roku wraz z GPT-3, skalujД…c do 175 miliardГіw parametrГіw (w porГіwnaniu do 1,5 miliarda w GPT-2). Ten ogromny wzrost skali w poЕӮД…czeniu z udoskonaleniami architektonicznymi wytworzyЕӮ jakoЕӣciowo rГіЕјne moЕјliwoЕӣci. GPT-3 mГіgЕӮ generowaДҮ tekst niezwykle przypominajД…cy tekst ludzki, rozumieДҮ kontekst tysiДҷcy sЕӮГіw, a nawet wykonywaДҮ zadania, do ktГіrych nie zostaЕӮ wyraЕәnie przeszkolony.
W przypadku konwersacyjnej sztucznej inteligencji te postДҷpy przeЕӮoЕјyЕӮy siДҷ na chatboty, ktГіre mogЕӮy:
ProwadziДҮ spГіjne konwersacje przez wiele tur
RozumieДҮ niuanse zapytaЕ„ bez wyraЕәnego szkolenia
GenerowaДҮ zrГіЕјnicowane, kontekstowo odpowiednie odpowiedzi
DostosowywaДҮ swГіj ton i styl do uЕјytkownika
RadziДҮ sobie z niejednoznacznoЕӣciД… i wyjaЕӣniaДҮ w razie potrzeby
Wydanie ChatGPT pod koniec 2022 r. wprowadziЕӮo te moЕјliwoЕӣci do gЕӮГіwnego nurtu, przyciД…gajД…c ponad milion uЕјytkownikГіw w ciД…gu kilku dni od premiery. Nagle ogГіЕӮ spoЕӮeczeЕ„stwa uzyskaЕӮ dostДҷp do konwersacyjnej sztucznej inteligencji, ktГіra wydawaЕӮa siДҷ jakoЕӣciowo inna od wszystkiego, co byЕӮo wczeЕӣniej вҖ“ bardziej elastyczna, bardziej kompetentna i bardziej naturalna w swoich interakcjach.
Szybko nastД…piЕӮy wdroЕјenia komercyjne, a firmy wЕӮД…czaЕӮy duЕјe modele jДҷzykowe do swoich platform obsЕӮugi klienta, narzДҷdzi do tworzenia treЕӣci i aplikacji zwiДҷkszajД…cych produktywnoЕӣДҮ. Szybkie przyjДҷcie tych modeli odzwierciedlaЕӮo zarГіwno skok technologiczny, jak i intuicyjny interfejs, jaki zapewniaЕӮy вҖ“ w koЕ„cu rozmowa jest najbardziej naturalnym sposobem komunikacji miДҷdzy ludЕәmi.
Ta innowacja umoЕјliwiЕӮa rozwГіj coraz potДҷЕјniejszych modeli jДҷzykowych. W 2018 roku Google wprowadziЕӮo BERT (Bidirectional Encoder Representations from Transformers), co radykalnie poprawiЕӮo wydajnoЕӣДҮ w rГіЕјnych zadaniach zwiД…zanych ze zrozumieniem jДҷzyka. W 2019 roku OpenAI wydaЕӮo GPT-2, demonstrujД…c bezprecedensowe moЕјliwoЕӣci generowania spГіjnego, kontekstowo istotnego tekstu.
Najbardziej spektakularny skok nastД…piЕӮ w 2020 roku wraz z GPT-3, skalujД…c do 175 miliardГіw parametrГіw (w porГіwnaniu do 1,5 miliarda w GPT-2). Ten ogromny wzrost skali w poЕӮД…czeniu z udoskonaleniami architektonicznymi wytworzyЕӮ jakoЕӣciowo rГіЕјne moЕјliwoЕӣci. GPT-3 mГіgЕӮ generowaДҮ tekst niezwykle przypominajД…cy tekst ludzki, rozumieДҮ kontekst tysiДҷcy sЕӮГіw, a nawet wykonywaДҮ zadania, do ktГіrych nie zostaЕӮ wyraЕәnie przeszkolony.
W przypadku konwersacyjnej sztucznej inteligencji te postДҷpy przeЕӮoЕјyЕӮy siДҷ na chatboty, ktГіre mogЕӮy:
ProwadziДҮ spГіjne konwersacje przez wiele tur
RozumieДҮ niuanse zapytaЕ„ bez wyraЕәnego szkolenia
GenerowaДҮ zrГіЕјnicowane, kontekstowo odpowiednie odpowiedzi
DostosowywaДҮ swГіj ton i styl do uЕјytkownika
RadziДҮ sobie z niejednoznacznoЕӣciД… i wyjaЕӣniaДҮ w razie potrzeby
Wydanie ChatGPT pod koniec 2022 r. wprowadziЕӮo te moЕјliwoЕӣci do gЕӮГіwnego nurtu, przyciД…gajД…c ponad milion uЕјytkownikГіw w ciД…gu kilku dni od premiery. Nagle ogГіЕӮ spoЕӮeczeЕ„stwa uzyskaЕӮ dostДҷp do konwersacyjnej sztucznej inteligencji, ktГіra wydawaЕӮa siДҷ jakoЕӣciowo inna od wszystkiego, co byЕӮo wczeЕӣniej вҖ“ bardziej elastyczna, bardziej kompetentna i bardziej naturalna w swoich interakcjach.
Szybko nastД…piЕӮy wdroЕјenia komercyjne, a firmy wЕӮД…czaЕӮy duЕјe modele jДҷzykowe do swoich platform obsЕӮugi klienta, narzДҷdzi do tworzenia treЕӣci i aplikacji zwiДҷkszajД…cych produktywnoЕӣДҮ. Szybkie przyjДҷcie tych modeli odzwierciedlaЕӮo zarГіwno skok technologiczny, jak i intuicyjny interfejs, jaki zapewniaЕӮy вҖ“ w koЕ„cu rozmowa jest najbardziej naturalnym sposobem komunikacji miДҷdzy ludЕәmi.
Przetestuj SWOJД„ FirmДҷ w Minuty
UtwГіrz konto i uruchom swojego chatbota AI w kilka minut. W peЕӮni konfigurowalny, bez koniecznoЕӣci kodowania - zacznij angaЕјowaДҮ swoich klientГіw natychmiast!
Gotowy w kilka minut
Nie wymaga programowania
100% bezpieczne
MoЕјliwoЕӣci multimodalne: poza rozmowami wyЕӮД…cznie tekstowymi
Podczas gdy tekst zdominowaЕӮ rozwГіj konwersacyjnej sztucznej inteligencji, w ostatnich latach nastД…piЕӮ wzrost w kierunku systemГіw multimodalnych, ktГіre mogД… rozumieДҮ i generowaДҮ wiele typГіw mediГіw. Ta ewolucja odzwierciedla fundamentalnД… prawdДҷ o komunikacji miДҷdzyludzkiej вҖ“ nie uЕјywamy tylko sЕӮГіw; gestykulujemy, pokazujemy obrazy, rysujemy diagramy i wykorzystujemy nasze otoczenie do przekazywania znaczenia.
Modele wizyjno-jДҷzykowe, takie jak DALL-E, Midjourney i Stable Diffusion, wykazaЕӮy zdolnoЕӣДҮ do generowania obrazГіw z opisГіw tekstowych, podczas gdy modele takie jak GPT-4 z moЕјliwoЕӣciami widzenia mogЕӮy analizowaДҮ obrazy i inteligentnie je omawiaДҮ. OtworzyЕӮo to nowe moЕјliwoЕӣci dla interfejsГіw konwersacyjnych:
Boty obsЕӮugi klienta, ktГіre mogД… analizowaДҮ zdjДҷcia uszkodzonych produktГіw
Asystenci zakupГіw, ktГіrzy mogД… identyfikowaДҮ przedmioty na podstawie obrazГіw i znajdowaДҮ podobne produkty
NarzДҷdzia edukacyjne, ktГіre mogД… wyjaЕӣniaДҮ diagramy i koncepcje wizualne
Funkcje uЕӮatwieЕ„ dostДҷpu, ktГіre mogД… opisywaДҮ obrazy dla uЕјytkownikГіw z dysfunkcjД… wzroku
MoЕјliwoЕӣci gЕӮosowe rГіwnieЕј znacznie siДҷ rozwinДҷЕӮy. Wczesne interfejsy gЕӮosowe, takie jak systemy IVR (Interactive Voice Response), byЕӮy notorycznie frustrujД…ce, ograniczone do sztywnych poleceЕ„ i struktur menu. WspГіЕӮczeЕӣni asystenci gЕӮosowi potrafiД… rozumieДҮ naturalne wzorce mowy, uwzglДҷdniaДҮ rГіЕјne akcenty i wady wymowy oraz odpowiadaДҮ coraz bardziej naturalnie brzmiД…cymi, syntezowanymi gЕӮosami.
PoЕӮД…czenie tych moЕјliwoЕӣci tworzy prawdziwie multimodalnД… konwersacyjnД… sztucznД… inteligencjДҷ, ktГіra moЕјe pЕӮynnie przeЕӮД…czaДҮ siДҷ miДҷdzy rГіЕјnymi trybami komunikacji w zaleЕјnoЕӣci od kontekstu i potrzeb uЕјytkownika. UЕјytkownik moЕјe zaczД…ДҮ od pytania tekstowego o naprawДҷ drukarki, wysЕӮaДҮ zdjДҷcie komunikatu o bЕӮДҷdzie, otrzymaДҮ diagram wyrГіЕјniajД…cy odpowiednie przyciski, a nastДҷpnie przeЕӮД…czyДҮ siДҷ na instrukcje gЕӮosowe, podczas gdy jego rДҷce sД… zajДҷte naprawД….
To multimodalne podejЕӣcie stanowi nie tylko postДҷp techniczny, ale fundamentalnД… zmianДҷ w kierunku bardziej naturalnej interakcji czЕӮowiek-komputer вҖ“ spotykanie siДҷ z uЕјytkownikami w dowolnym trybie komunikacji, ktГіry najlepiej sprawdza siДҷ w ich obecnym kontekЕӣcie i potrzebach.
Modele wizyjno-jДҷzykowe, takie jak DALL-E, Midjourney i Stable Diffusion, wykazaЕӮy zdolnoЕӣДҮ do generowania obrazГіw z opisГіw tekstowych, podczas gdy modele takie jak GPT-4 z moЕјliwoЕӣciami widzenia mogЕӮy analizowaДҮ obrazy i inteligentnie je omawiaДҮ. OtworzyЕӮo to nowe moЕјliwoЕӣci dla interfejsГіw konwersacyjnych:
Boty obsЕӮugi klienta, ktГіre mogД… analizowaДҮ zdjДҷcia uszkodzonych produktГіw
Asystenci zakupГіw, ktГіrzy mogД… identyfikowaДҮ przedmioty na podstawie obrazГіw i znajdowaДҮ podobne produkty
NarzДҷdzia edukacyjne, ktГіre mogД… wyjaЕӣniaДҮ diagramy i koncepcje wizualne
Funkcje uЕӮatwieЕ„ dostДҷpu, ktГіre mogД… opisywaДҮ obrazy dla uЕјytkownikГіw z dysfunkcjД… wzroku
MoЕјliwoЕӣci gЕӮosowe rГіwnieЕј znacznie siДҷ rozwinДҷЕӮy. Wczesne interfejsy gЕӮosowe, takie jak systemy IVR (Interactive Voice Response), byЕӮy notorycznie frustrujД…ce, ograniczone do sztywnych poleceЕ„ i struktur menu. WspГіЕӮczeЕӣni asystenci gЕӮosowi potrafiД… rozumieДҮ naturalne wzorce mowy, uwzglДҷdniaДҮ rГіЕјne akcenty i wady wymowy oraz odpowiadaДҮ coraz bardziej naturalnie brzmiД…cymi, syntezowanymi gЕӮosami.
PoЕӮД…czenie tych moЕјliwoЕӣci tworzy prawdziwie multimodalnД… konwersacyjnД… sztucznД… inteligencjДҷ, ktГіra moЕјe pЕӮynnie przeЕӮД…czaДҮ siДҷ miДҷdzy rГіЕјnymi trybami komunikacji w zaleЕјnoЕӣci od kontekstu i potrzeb uЕјytkownika. UЕјytkownik moЕјe zaczД…ДҮ od pytania tekstowego o naprawДҷ drukarki, wysЕӮaДҮ zdjДҷcie komunikatu o bЕӮДҷdzie, otrzymaДҮ diagram wyrГіЕјniajД…cy odpowiednie przyciski, a nastДҷpnie przeЕӮД…czyДҮ siДҷ na instrukcje gЕӮosowe, podczas gdy jego rДҷce sД… zajДҷte naprawД….
To multimodalne podejЕӣcie stanowi nie tylko postДҷp techniczny, ale fundamentalnД… zmianДҷ w kierunku bardziej naturalnej interakcji czЕӮowiek-komputer вҖ“ spotykanie siДҷ z uЕјytkownikami w dowolnym trybie komunikacji, ktГіry najlepiej sprawdza siДҷ w ich obecnym kontekЕӣcie i potrzebach.
Generacja wzbogacona o wyszukiwanie: ugruntowanie sztucznej inteligencji w faktach
Pomimo imponujД…cych moЕјliwoЕӣci, duЕјe modele jДҷzykowe majД… nieodЕӮД…czne ograniczenia. MogД… вҖһhalucynowaДҮвҖқ informacje, pewnie podajД…c fakty brzmiД…ce wiarygodnie, ale nieprawdziwe. Ich wiedza ogranicza siДҷ do tego, co znajdowaЕӮo siДҷ w ich danych treningowych, tworzД…c datДҷ granicznД… wiedzy. Brakuje im rГіwnieЕј moЕјliwoЕӣci dostДҷpu do informacji w czasie rzeczywistym lub specjalistycznych baz danych, chyba Ејe zostaЕӮy specjalnie zaprojektowane do tego celu.
Pobieranie-Rozszerzona Generacja (RAG) wyЕӮoniЕӮo siДҷ jako rozwiД…zanie tych wyzwaЕ„. Zamiast polegaДҮ wyЕӮД…cznie na parametrach nauczonych podczas treningu, systemy RAG ЕӮД…czД… zdolnoЕӣci generatywne modeli jДҷzykowych z mechanizmami pobierania, ktГіre mogД… uzyskiwaДҮ dostДҷp do zewnДҷtrznych ЕәrГіdeЕӮ wiedzy.
Typowa architektura RAG dziaЕӮa w nastДҷpujД…cy sposГіb:
System otrzymuje zapytanie uЕјytkownika
Przeszukuje odpowiednie bazy wiedzy pod kД…tem informacji istotnych dla zapytania
Przekazuje zarГіwno zapytanie, jak i pobrane informacje do modelu jДҷzykowego
Model generuje odpowiedЕә opartД… na pobranych faktach
To podejЕӣcie oferuje kilka zalet:
DokЕӮadniejsze, faktyczne odpowiedzi dziДҷki ugruntowaniu generowania w zweryfikowanych informacjach
MoЕјliwoЕӣДҮ dostДҷpu do aktualnych informacji wykraczajД…cych poza odciДҷcie szkoleniowe modelu
Specjalistyczna wiedza ze ЕәrГіdeЕӮ specyficznych dla domeny, takich jak dokumentacja firmy
PrzejrzystoЕӣДҮ i atrybucja poprzez cytowanie ЕәrГіdeЕӮ informacji
Dla firm wdraЕјajД…cych konwersacyjnД… sztucznД… inteligencjДҷ RAG okazaЕӮ siДҷ szczegГіlnie cenny w przypadku aplikacji obsЕӮugi klienta. Na przykЕӮad chatbot bankowy moЕјe uzyskaДҮ dostДҷp do najnowszych dokumentГіw polis, informacji o kontach i rejestrГіw transakcji, aby zapewniДҮ dokЕӮadne, spersonalizowane odpowiedzi, ktГіre byЕӮyby niemoЕјliwe w przypadku samodzielnego modelu jДҷzykowego. RozwГіj systemГіw RAG przebiega nieustannie, co przejawia siДҷ w udoskonalaniu dokЕӮadnoЕӣci wyszukiwania, wprowadzaniu bardziej zaawansowanych metod integrowania wyszukanych informacji z wygenerowanym tekstem oraz udoskonalaniu mechanizmГіw oceny wiarygodnoЕӣci rГіЕјnych ЕәrГіdeЕӮ informacji.
Pobieranie-Rozszerzona Generacja (RAG) wyЕӮoniЕӮo siДҷ jako rozwiД…zanie tych wyzwaЕ„. Zamiast polegaДҮ wyЕӮД…cznie na parametrach nauczonych podczas treningu, systemy RAG ЕӮД…czД… zdolnoЕӣci generatywne modeli jДҷzykowych z mechanizmami pobierania, ktГіre mogД… uzyskiwaДҮ dostДҷp do zewnДҷtrznych ЕәrГіdeЕӮ wiedzy.
Typowa architektura RAG dziaЕӮa w nastДҷpujД…cy sposГіb:
System otrzymuje zapytanie uЕјytkownika
Przeszukuje odpowiednie bazy wiedzy pod kД…tem informacji istotnych dla zapytania
Przekazuje zarГіwno zapytanie, jak i pobrane informacje do modelu jДҷzykowego
Model generuje odpowiedЕә opartД… na pobranych faktach
To podejЕӣcie oferuje kilka zalet:
DokЕӮadniejsze, faktyczne odpowiedzi dziДҷki ugruntowaniu generowania w zweryfikowanych informacjach
MoЕјliwoЕӣДҮ dostДҷpu do aktualnych informacji wykraczajД…cych poza odciДҷcie szkoleniowe modelu
Specjalistyczna wiedza ze ЕәrГіdeЕӮ specyficznych dla domeny, takich jak dokumentacja firmy
PrzejrzystoЕӣДҮ i atrybucja poprzez cytowanie ЕәrГіdeЕӮ informacji
Dla firm wdraЕјajД…cych konwersacyjnД… sztucznД… inteligencjДҷ RAG okazaЕӮ siДҷ szczegГіlnie cenny w przypadku aplikacji obsЕӮugi klienta. Na przykЕӮad chatbot bankowy moЕјe uzyskaДҮ dostДҷp do najnowszych dokumentГіw polis, informacji o kontach i rejestrГіw transakcji, aby zapewniДҮ dokЕӮadne, spersonalizowane odpowiedzi, ktГіre byЕӮyby niemoЕјliwe w przypadku samodzielnego modelu jДҷzykowego. RozwГіj systemГіw RAG przebiega nieustannie, co przejawia siДҷ w udoskonalaniu dokЕӮadnoЕӣci wyszukiwania, wprowadzaniu bardziej zaawansowanych metod integrowania wyszukanych informacji z wygenerowanym tekstem oraz udoskonalaniu mechanizmГіw oceny wiarygodnoЕӣci rГіЕјnych ЕәrГіdeЕӮ informacji.
Model wspГіЕӮpracy czЕӮowieka ze sztucznД… inteligencjД…: znalezienie wЕӮaЕӣciwej rГіwnowagi
Wraz z rozwojem moЕјliwoЕӣci konwersacyjnej AI, ewoluowaЕӮa relacja miДҷdzy ludЕәmi a systemami AI. Wczesne chatboty byЕӮy wyraЕәnie pozycjonowane jako narzДҷdzia вҖ“ o ograniczonym zakresie i ewidentnie nieludzkie w swoich interakcjach. Nowoczesne systemy zacierajД… te granice, tworzД…c nowe pytania o to, jak zaprojektowaДҮ skutecznД… wspГіЕӮpracДҷ czЕӮowieka ze sztucznД… inteligencjД….
Najbardziej udane implementacje obecnie opierajД… siДҷ na modelu wspГіЕӮpracy, w ktГіrym:
AI obsЕӮuguje rutynowe, powtarzalne zapytania, ktГіre nie wymagajД… ludzkiej oceny
Ludzie koncentrujД… siДҷ na zЕӮoЕјonych przypadkach wymagajД…cych empatii, etycznego rozumowania lub kreatywnego rozwiД…zywania problemГіw
System zna swoje ograniczenia i pЕӮynnie eskaluje do ludzkich agentГіw, gdy jest to odpowiednie
PrzejЕӣcie miДҷdzy AI a wsparciem ludzkim jest pЕӮynne dla uЕјytkownika
Ludzcy agenci majД… peЕӮny kontekst historii rozmГіw z AI
AI nadal uczy siДҷ z interwencji czЕӮowieka, stopniowo rozszerzajД…c swoje moЕјliwoЕӣci
To podejЕӣcie uznaje, Ејe konwersacyjna AI nie powinna mieДҮ na celu caЕӮkowitego zastД…pienia interakcji czЕӮowieka, ale raczej jej uzupeЕӮnienia вҖ“ obsЕӮugi duЕјej liczby prostych zapytaЕ„, ktГіre pochЕӮaniajД… czas ludzkich agentГіw, jednoczeЕӣnie zapewniajД…c, Ејe zЕӮoЕјone problemy docierajД… do odpowiedniej ludzkiej wiedzy specjalistycznej. WdroЕјenie tego modelu rГіЕјni siДҷ w zaleЕјnoЕӣci od branЕјy. W opiece zdrowotnej chatboty AI mogД… obsЕӮugiwaДҮ planowanie wizyt i podstawowe badanie objawГіw, zapewniajД…c jednoczeЕӣnie, Ејe porady medyczne pochodzД… od wykwalifikowanych specjalistГіw. W usЕӮugach prawnych AI moЕјe pomagaДҮ w przygotowywaniu dokumentГіw i badaniach, pozostawiajД…c interpretacjДҷ i strategiДҷ prawnikom. W obsЕӮudze klienta AI moЕјe rozwiД…zywaДҮ typowe problemy, kierujД…c zЕӮoЕјone problemy do wyspecjalizowanych agentГіw.
W miarДҷ rozwoju moЕјliwoЕӣci AI granica miДҷdzy tym, co wymaga zaangaЕјowania czЕӮowieka, a tym, co moЕјna zautomatyzowaДҮ, bДҷdzie siДҷ przesuwaДҮ, ale podstawowa zasada pozostaje: skuteczna konwersacyjna AI powinna wzmacniaДҮ ludzkie moЕјliwoЕӣci, a nie po prostu je zastДҷpowaДҮ.
Najbardziej udane implementacje obecnie opierajД… siДҷ na modelu wspГіЕӮpracy, w ktГіrym:
AI obsЕӮuguje rutynowe, powtarzalne zapytania, ktГіre nie wymagajД… ludzkiej oceny
Ludzie koncentrujД… siДҷ na zЕӮoЕјonych przypadkach wymagajД…cych empatii, etycznego rozumowania lub kreatywnego rozwiД…zywania problemГіw
System zna swoje ograniczenia i pЕӮynnie eskaluje do ludzkich agentГіw, gdy jest to odpowiednie
PrzejЕӣcie miДҷdzy AI a wsparciem ludzkim jest pЕӮynne dla uЕјytkownika
Ludzcy agenci majД… peЕӮny kontekst historii rozmГіw z AI
AI nadal uczy siДҷ z interwencji czЕӮowieka, stopniowo rozszerzajД…c swoje moЕјliwoЕӣci
To podejЕӣcie uznaje, Ејe konwersacyjna AI nie powinna mieДҮ na celu caЕӮkowitego zastД…pienia interakcji czЕӮowieka, ale raczej jej uzupeЕӮnienia вҖ“ obsЕӮugi duЕјej liczby prostych zapytaЕ„, ktГіre pochЕӮaniajД… czas ludzkich agentГіw, jednoczeЕӣnie zapewniajД…c, Ејe zЕӮoЕјone problemy docierajД… do odpowiedniej ludzkiej wiedzy specjalistycznej. WdroЕјenie tego modelu rГіЕјni siДҷ w zaleЕјnoЕӣci od branЕјy. W opiece zdrowotnej chatboty AI mogД… obsЕӮugiwaДҮ planowanie wizyt i podstawowe badanie objawГіw, zapewniajД…c jednoczeЕӣnie, Ејe porady medyczne pochodzД… od wykwalifikowanych specjalistГіw. W usЕӮugach prawnych AI moЕјe pomagaДҮ w przygotowywaniu dokumentГіw i badaniach, pozostawiajД…c interpretacjДҷ i strategiДҷ prawnikom. W obsЕӮudze klienta AI moЕјe rozwiД…zywaДҮ typowe problemy, kierujД…c zЕӮoЕјone problemy do wyspecjalizowanych agentГіw.
W miarДҷ rozwoju moЕјliwoЕӣci AI granica miДҷdzy tym, co wymaga zaangaЕјowania czЕӮowieka, a tym, co moЕјna zautomatyzowaДҮ, bДҷdzie siДҷ przesuwaДҮ, ale podstawowa zasada pozostaje: skuteczna konwersacyjna AI powinna wzmacniaДҮ ludzkie moЕјliwoЕӣci, a nie po prostu je zastДҷpowaДҮ.
PrzyszЕӮy krajobraz: dokД…d zmierza sztuczna inteligencja konwersacyjna
PatrzД…c w przyszЕӮoЕӣДҮ, widzimy kilka pojawiajД…cych siДҷ trendГіw ksztaЕӮtujД…cych przyszЕӮoЕӣДҮ konwersacyjnej sztucznej inteligencji. Te zmiany obiecujД… nie tylko stopniowe ulepszenia, ale potencjalnie transformacyjne zmiany w sposobie interakcji z technologiД….
Personalizacja na duЕјД… skalДҷ: PrzyszЕӮe systemy bДҷdД… coraz czДҷЕӣciej dostosowywaДҮ swoje odpowiedzi nie tylko do bezpoЕӣredniego kontekstu, ale takЕјe do stylu komunikacji, preferencji, poziomu wiedzy i historii relacji kaЕјdego uЕјytkownika. Ta personalizacja sprawi, Ејe interakcje bДҷdД… wydawaДҮ siДҷ bardziej naturalne i istotne, choДҮ rodzi waЕјne pytania dotyczД…ce prywatnoЕӣci i wykorzystania danych.
Inteligencja emocjonalna: Podczas gdy dzisiejsze systemy potrafiД… wykrywaДҮ podstawowe nastroje, przyszЕӮa konwersacyjna sztuczna inteligencja rozwinie bardziej wyrafinowanД… inteligencjДҷ emocjonalnД… вҖ“ rozpoznajД…c subtelne stany emocjonalne, odpowiednio reagujД…c na niepokГіj lub frustracjДҷ i odpowiednio dostosowujД…c swГіj ton i podejЕӣcie. Ta zdolnoЕӣДҮ bДҷdzie szczegГіlnie cenna w obsЕӮudze klienta, opiece zdrowotnej i aplikacjach edukacyjnych.
Proaktywna pomoc: Zamiast czekaДҮ na wyraЕәne zapytania, systemy konwersacyjne nowej generacji bДҷdД… przewidywaДҮ potrzeby na podstawie kontekstu, historii uЕјytkownika i sygnaЕӮГіw Еӣrodowiskowych. System moЕјe zauwaЕјyДҮ, Ејe planujesz kilka spotkaЕ„ w nieznanym mieЕӣcie i proaktywnie zaproponowaДҮ opcje transportu lub prognozy pogody.
Bezproblemowa integracja multimodalna: PrzyszЕӮe systemy wykroczД… poza proste wspieranie rГіЕјnych modalnoЕӣci, aby pЕӮynnie je integrowaДҮ. Rozmowa moЕјe pЕӮynД…ДҮ naturalnie miДҷdzy tekstem, gЕӮosem, obrazami i elementami interaktywnymi, wybierajД…c odpowiedniД… modalnoЕӣДҮ dla kaЕјdej informacji bez koniecznoЕӣci wyraЕәnego wyboru uЕјytkownika.
Eksperci wyspecjalizowani w danej dziedzinie: Podczas gdy asystenci ogГіlnego przeznaczenia bДҷdД… siДҷ nadal rozwijaДҮ, zobaczymy rГіwnieЕј wzrost wysoce wyspecjalizowanej konwersacyjnej sztucznej inteligencji z gЕӮДҷbokД… wiedzД… specjalistycznД… w okreЕӣlonych dziedzinach вҖ“ asystentГіw prawnych, ktГіrzy rozumiejД… orzecznictwo i precedensy, systemГіw medycznych z kompleksowД… wiedzД… na temat interakcji lekГіw i protokoЕӮГіw leczenia lub doradcГіw finansowych znajД…cych siДҷ na kodeksach podatkowych i strategiach inwestycyjnych.
NaprawdДҷ ciД…gЕӮa nauka: PrzyszЕӮe systemy wykroczД… poza okresowe przekwalifikowanie, aby wykroczyДҮ poza ciД…gЕӮД… naukДҷ na podstawie interakcji, stajД…c siДҷ z czasem bardziej pomocnymi i spersonalizowanymi, przy jednoczesnym zachowaniu odpowiednich zabezpieczeЕ„ prywatnoЕӣci.
Pomimo tych ekscytujД…cych moЕјliwoЕӣci, wyzwania pozostajД…. Obawy dotyczД…ce prywatnoЕӣci, ЕӮagodzenie stronniczoЕӣci, odpowiednia przejrzystoЕӣДҮ i ustanowienie wЕӮaЕӣciwego poziomu nadzoru ze strony czЕӮowieka to bieЕјД…ce kwestie, ktГіre bДҷdД… ksztaЕӮtowaДҮ zarГіwno technologiДҷ, jak i jej regulacje. Najbardziej udane wdroЕјenia to te, ktГіre podejmД… te wyzwania w sposГіb przemyЕӣlany, zapewniajД…c jednoczeЕӣnie uЕјytkownikom prawdziwД… wartoЕӣДҮ.
Jasne jest, Ејe konwersacyjna sztuczna inteligencja przeszЕӮa z niszowej technologii do gЕӮГіwnego nurtu paradygmatu interfejsu, ktГіry bДҷdzie coraz bardziej poЕӣredniczyЕӮ w naszych interakcjach z systemami cyfrowymi. Ewolucyjna ЕӣcieЕјka od prostego dopasowywania wzorcГіw ELIZA do dzisiejszych wyrafinowanych modeli jДҷzykowych stanowi jeden z najwaЕјniejszych postДҷpГіw w interakcji czЕӮowiek-komputer вҖ“ a podrГіЕј ta jest daleka od zakoЕ„czenia.
Personalizacja na duЕјД… skalДҷ: PrzyszЕӮe systemy bДҷdД… coraz czДҷЕӣciej dostosowywaДҮ swoje odpowiedzi nie tylko do bezpoЕӣredniego kontekstu, ale takЕјe do stylu komunikacji, preferencji, poziomu wiedzy i historii relacji kaЕјdego uЕјytkownika. Ta personalizacja sprawi, Ејe interakcje bДҷdД… wydawaДҮ siДҷ bardziej naturalne i istotne, choДҮ rodzi waЕјne pytania dotyczД…ce prywatnoЕӣci i wykorzystania danych.
Inteligencja emocjonalna: Podczas gdy dzisiejsze systemy potrafiД… wykrywaДҮ podstawowe nastroje, przyszЕӮa konwersacyjna sztuczna inteligencja rozwinie bardziej wyrafinowanД… inteligencjДҷ emocjonalnД… вҖ“ rozpoznajД…c subtelne stany emocjonalne, odpowiednio reagujД…c na niepokГіj lub frustracjДҷ i odpowiednio dostosowujД…c swГіj ton i podejЕӣcie. Ta zdolnoЕӣДҮ bДҷdzie szczegГіlnie cenna w obsЕӮudze klienta, opiece zdrowotnej i aplikacjach edukacyjnych.
Proaktywna pomoc: Zamiast czekaДҮ na wyraЕәne zapytania, systemy konwersacyjne nowej generacji bДҷdД… przewidywaДҮ potrzeby na podstawie kontekstu, historii uЕјytkownika i sygnaЕӮГіw Еӣrodowiskowych. System moЕјe zauwaЕјyДҮ, Ејe planujesz kilka spotkaЕ„ w nieznanym mieЕӣcie i proaktywnie zaproponowaДҮ opcje transportu lub prognozy pogody.
Bezproblemowa integracja multimodalna: PrzyszЕӮe systemy wykroczД… poza proste wspieranie rГіЕјnych modalnoЕӣci, aby pЕӮynnie je integrowaДҮ. Rozmowa moЕјe pЕӮynД…ДҮ naturalnie miДҷdzy tekstem, gЕӮosem, obrazami i elementami interaktywnymi, wybierajД…c odpowiedniД… modalnoЕӣДҮ dla kaЕјdej informacji bez koniecznoЕӣci wyraЕәnego wyboru uЕјytkownika.
Eksperci wyspecjalizowani w danej dziedzinie: Podczas gdy asystenci ogГіlnego przeznaczenia bДҷdД… siДҷ nadal rozwijaДҮ, zobaczymy rГіwnieЕј wzrost wysoce wyspecjalizowanej konwersacyjnej sztucznej inteligencji z gЕӮДҷbokД… wiedzД… specjalistycznД… w okreЕӣlonych dziedzinach вҖ“ asystentГіw prawnych, ktГіrzy rozumiejД… orzecznictwo i precedensy, systemГіw medycznych z kompleksowД… wiedzД… na temat interakcji lekГіw i protokoЕӮГіw leczenia lub doradcГіw finansowych znajД…cych siДҷ na kodeksach podatkowych i strategiach inwestycyjnych.
NaprawdДҷ ciД…gЕӮa nauka: PrzyszЕӮe systemy wykroczД… poza okresowe przekwalifikowanie, aby wykroczyДҮ poza ciД…gЕӮД… naukДҷ na podstawie interakcji, stajД…c siДҷ z czasem bardziej pomocnymi i spersonalizowanymi, przy jednoczesnym zachowaniu odpowiednich zabezpieczeЕ„ prywatnoЕӣci.
Pomimo tych ekscytujД…cych moЕјliwoЕӣci, wyzwania pozostajД…. Obawy dotyczД…ce prywatnoЕӣci, ЕӮagodzenie stronniczoЕӣci, odpowiednia przejrzystoЕӣДҮ i ustanowienie wЕӮaЕӣciwego poziomu nadzoru ze strony czЕӮowieka to bieЕјД…ce kwestie, ktГіre bДҷdД… ksztaЕӮtowaДҮ zarГіwno technologiДҷ, jak i jej regulacje. Najbardziej udane wdroЕјenia to te, ktГіre podejmД… te wyzwania w sposГіb przemyЕӣlany, zapewniajД…c jednoczeЕӣnie uЕјytkownikom prawdziwД… wartoЕӣДҮ.
Jasne jest, Ејe konwersacyjna sztuczna inteligencja przeszЕӮa z niszowej technologii do gЕӮГіwnego nurtu paradygmatu interfejsu, ktГіry bДҷdzie coraz bardziej poЕӣredniczyЕӮ w naszych interakcjach z systemami cyfrowymi. Ewolucyjna ЕӣcieЕјka od prostego dopasowywania wzorcГіw ELIZA do dzisiejszych wyrafinowanych modeli jДҷzykowych stanowi jeden z najwaЕјniejszych postДҷpГіw w interakcji czЕӮowiek-komputer вҖ“ a podrГіЕј ta jest daleka od zakoЕ„czenia.





